任务简介
首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示:
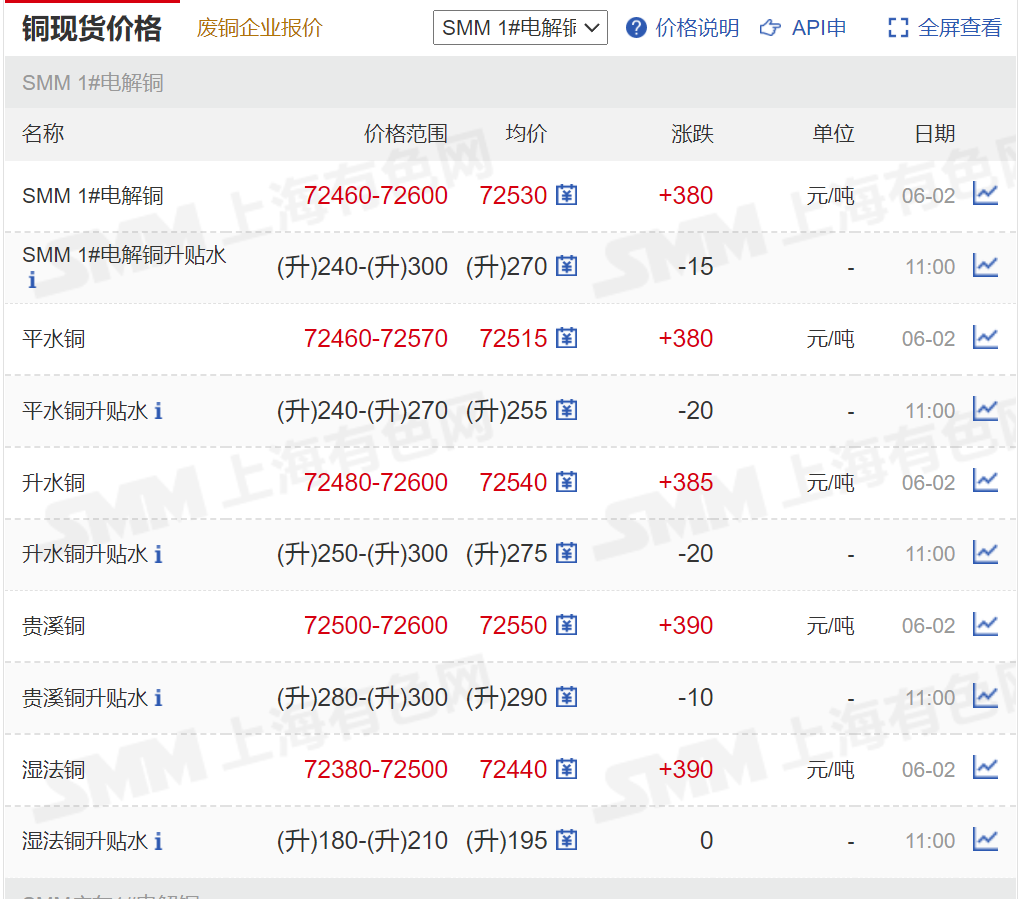
如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可。但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金……

数据的价值!!!
鉴于,客户需求仅仅是“沪铜CU2206”一项期货的历史价格,氪金会员性价比不高,因此,实际的任务目标变为如何获取的历史价格,目标变为全网有公开提供数据的网址。而最终解决该问题,是求助于万能的百度^_^。找到了合适的网站,且获取数据的难度也几乎降到了最低难度。
解决步骤
- 百度搜索资源:这个步骤是整个任务完整的最难点(实际不难),但这里卖个关子,全文不公布最终找到的网站,大家试试看能否搜索到,以及花费多少时间^_^。
- 解析网站的请求,最终找到的网站经解析后,发现获取数据是通过get的方式提交参数。而请求的参数如下:/price?starttime=1638545822&endtime=1654357022&classid=48,一看就知是开始时间、结束时间的时间戳,以及商品id。再解析headers,居然连cookie都不需要,说明没有反爬!没有反爬!没有反爬!不得不说运气爆棚!
- 解析响应数据:由于响应数据是规整的json格式数据,使用pandas的read_json直接能够获取dataframe格式的数据,该步骤也并无难度。
代码实现
鉴于网站没有反爬,且参数简单,实际上的任务主要是规划一下如何设计增量更新数据信息的流程,具体代码如下:
声明:本站所有资源,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。