pandas 介绍
❓ Pandas 是什么?
 熊猫?14年网龄的我,早就在互联网发表情包了,这种熊猫表情包我可太熟悉了。
熊猫?14年网龄的我,早就在互联网发表情包了,这种熊猫表情包我可太熟悉了。
但是我们今天要说的是 Python 里的 pandas,为了接地气本篇所有用的表情包都会是熊猫头。
” pandas 就是一个用于数据处理和分析的 python 库 ”
pandas 支持读取和处理各种外部资源数据,比如读取 CSV 文件、文本文件、Excel 文件、web 数据等,还可以使用 matplotlib 可视化数据。
 先提一嘴 pandas 的数据结构:
先提一嘴 pandas 的数据结构:
- 一维数据结构:Series
- 二维数据结构:Data Frame
- 三维数据结构:Panel
pandas 在数据中支持多种运算函数,使用 pandas 库需要引入头文件:
import pandas as pd
 一般会 as pd 一下,这样用起来能更方便些。(就像 numpy 我们习惯去 as np 一样)
一般会 as pd 一下,这样用起来能更方便些。(就像 numpy 我们习惯去 as np 一样)
numpy 数组是所有元素都相同的数据类型,但 pandas 允许元素的数据类型不同,并生成结构数,比如 Series 和 DataFrame。
Series 数据结构
 简单的一维数据结构,能展示出带有索引 (index) 的一维数组。
简单的一维数据结构,能展示出带有索引 (index) 的一维数组。
与 Numpy 中的一维 array 类似。它们都和 Python 基本的数据结构 List 相似。
现在的 Series 能保存不同数据类型,字符串、boolean 值、数字等,它们都能保存在 Series 中。
用法演示:使用 pd.Series() 函数
可以指定参数 index,如果不指定 index 会默认从 0 开始。
s2 = pd.Series(data, index = [“安娜”, “末日铁拳”, “麦克雷”, “莱因哈特”, “禅雅塔”])
print(s1, “\n\n”, s2, “\n”)
运行结果:

用法演示:使用字典数据创建 Series
会将字典的键配置为 index,将字典的值配置为 values。
{“苹果”: “Apple”, “橘子”: “Orange”, “香蕉”: “banana”, “桃子”: “peach”}
运行结果

DataFrame 数据结构
 二维的表格型数据结构,DataFrame 接受带行和列的表数据。
二维的表格型数据结构,DataFrame 接受带行和列的表数据。
- index 和列具有各自的标签(名称)
- 每个列可以有不同的数据类型
- 默认情况下,按列管理数据
可以将 DataFrame 理解为 Series 的容器。
可以将多种数据类型的数据转换为 Data Frame 数据结构:
- 字典、列表、nd-array 对象、Series 数据结构
- 使用 pd.DataFrame() 函数创建
- 生成的默认索引为从 0 开始的整数
- 可使用 index 关键字命名索引
- 可使用 columns 关键字命名列
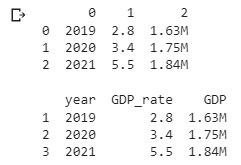
用法演示:使用 pd.DataFrame()
index = [1, 2, 3], # 指定索引
columns = [‘year’, ‘GDP_rate’, ‘GDP’] # 指定列
运行结果:
用法演示: 使用字典数据创建 DataFrame(字典的键为列名,字典的值为列值)
data = {“year” : [2019, 2020, 2021],
“GDP_rate” : [2.8, 3.4, 3.0],
“GDP” : [“1.63M”, “1.75M”, “1.83M”]
df = pd.DataFrame(data) # 等同于 df = pd.DataFrame(data=data)
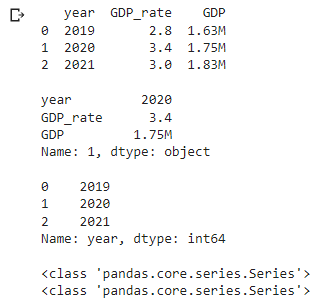
print(df.iloc[1], “\n”) # row 引用类型:df.loc[index名称],df.iloc[index编号]
print(df[“year”], “\n”) # 等同于 print(df.year)
# column 引用方法:df[“列名”] 或 df.列名
运行结果
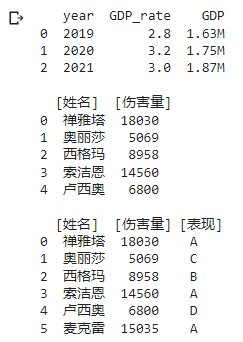
操作演示:如果在添加行时将其指定为现有索引名称,则会修改现有的数据值。
s1 = pd.Series( [2019, 2020, 2021] )
s2 = pd.Series( [2.8, 3.2, 3.0] )
s3 = pd.Series( [“1.63M”, “1.75M”, “1.87M”] )
data = {“year” : s1, “GDP_rate” : s2, “GDP” : s3}
names = pd.Series([“禅雅塔”, “奥丽莎”, “西格玛”, “索洁恩”, “卢西奥”])
scores = pd.Series([18030, 5069, 8958, 14560, 6800])
members = {“[姓名]”: names, “[伤害量]” : scores}
df2 = pd.DataFrame(members)
df2[“[表现]”] = [“A”, “C”, “B”, “A”, “D”] # 列名以 Grade 添加列
df2.loc[5] = [“麦克雷”, 15035, “A”] # 添加行
运行结果:
 我们之前提到了,numpy 也是可以塞里面的,我们来看看。
我们之前提到了,numpy 也是可以塞里面的,我们来看看。
[ [1, 2, 3], [4, 5, 6] ] # 创建一个二维数组
df1 = pd.DataFrame(data1)
{“苹果”: “Apple”, “橙子”: “Orange”,
“香蕉”: “banana”, “桃子”: “peach”}
df2 = pd.DataFrame(data2, columns = [“英文名”])
运行结果:

索引与数据选择
刚才在注释里我们演示了一些 “数据引用”,现在我们现在来正式讲一下这个知识点。

我们假设变量 df 是 DataFrame 的对象:
列值索引:
df[[列名1, 列名2, …]] # 如果有多行要引用,可以写到列表里
切片作为索引:
df[起始位置, 结束位置] # 从 start 开始到 end-1 行
行索引:
df.loc[[行名1, 行名2, …]] # 如果有多行要引用,可以写到列表里
索引单个元素:
df.loc[行名, 列名]
使用布尔索引 (boolean indexing) 引用符合条件的值:
df[条件式] # 仅引用满足条件表达式的数据
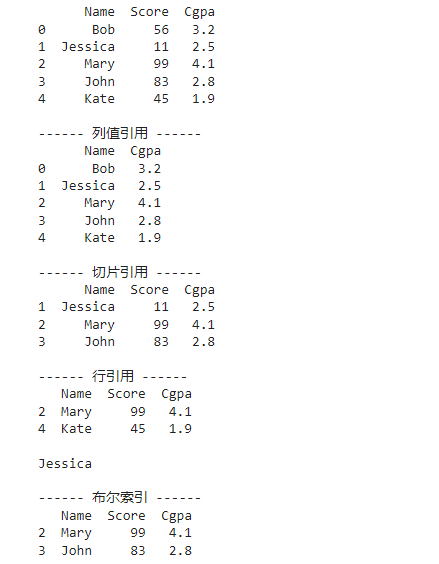
用法演示:数据索引
names = [“Bob”, “Jessica”, “Mary”, “John”, “Kate”]
scores = [56, 11, 99, 83, 45]
members = {“Name”: names, “Score”: scores}
df = pd.DataFrame(data=members)
[3.2, 2.5, 4.1, 2.8, 1.9]
print(df[[“Name”, “Cgpa”]], “\n”)
print(df.loc[[2, 4]], “\n”)
print(df.loc[1, “Name”], “\n”)
print(df[df.Score > 60]) # 筛出分数大于60的
运行结果:
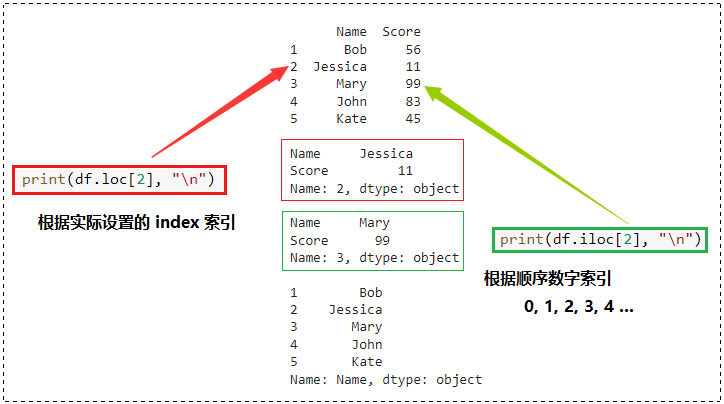
loc 指的是 location,iloc 中的 i 是指的是 integer,这两者的区别如下:
- loc:根据实际设置的 index 来索引数据
- iloc:根据顺序数字来索引数据
names = [“Bob”, “Jessica”, “Mary”, “John”, “Kate”]
scores = [56, 11, 99, 83, 45]
members = {“Name”: names, “Score”: scores}
df = pd.DataFrame(data = members, index = range(1, 6))
运行结果:
获取对数据进行排序的新对象
使用 DataFrame 对象的 sort_values(by=列名) 函数,按 by 参数指定的值排序(默认为升序)。
参数 ascending 值为 False 时,按降序排序。
根据引用,初始化 DataFrame 对象索引的新对象。
使用 reset_index() 函数获取初始化 DataFrame 对象索引的新对象。将参数 drop 值设置为 True 时为升序。
用法演示:sort_values() 与 reset_index()
names = [“Bob”, “Jessica”, “Mary”, “John”, “Kate”]
scores = [56, 11, 99, 83, 45]
members = {“Name”: names, “Score”: scores}
df = pd.DataFrame(members)
df[“Grade”] = [“C”, “F”, “A”, “B”, “D”]
df.loc[5] = [“Hanna”, 90, “A”]
df1 = df.sort_values(by = “Score”, ascending = False)
df2 = df1.reset_index(drop = True)
运行结果:
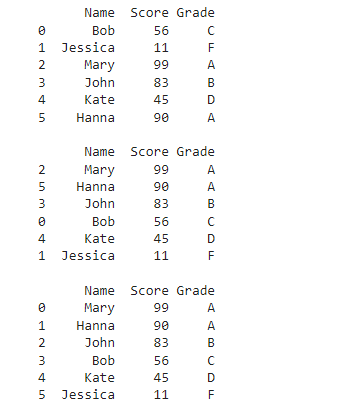
DataFrame 为对象增加新列
缺失值处理:大多数实际数据都是未精炼的,存在缺失值,不同的数据具有不同形式的缺失值(缺失值)。结构性数据标记为 null、NaN、NA 等。
names = [“Bob”, “Jessica”, “Mary”, “John”, “Kate”]
scores = [56, 11, 99, 83, 45]
members = {“Name”: names, “Score”: scores}
df = pd.DataFrame(members)
df[“Grade”] = np.nan # 不指定数据时只增加列
df.loc[2, “Grade”] = “A” # 在现有行的追加的列中储存数据
df.loc[5, “Grade”] = “F” # 追加新的行,在指定列中储存数据,剩下的数据以 Nan 形式初始化
运行结果:
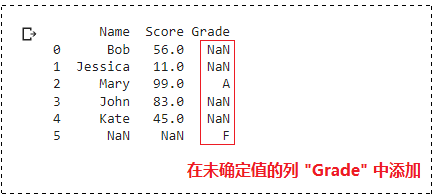
缺失值处理演示:
a = np.array([1, 2, np.nan, 4, 5])
print(a.sum(), a.min(), a.max())
print(np.nansum(a), np.nanmin(a), np.nanmax(a)) # 对非 nan 值计算
运行结果:

读取外部文件数据(CSV文件)
 pandas 可以读取和写入各种外部数据,包括 CSV 文件、Excel 文件和文本文件。
pandas 可以读取和写入各种外部数据,包括 CSV 文件、Excel 文件和文本文件。
读取CSV文件(扩展名 .csv)以创建并返回 DataFrame 对象的函数:
read_csv("文件名")
CSV 文件以逗号(,)分隔数据,并由表示记录的行和表示字段的列组成。
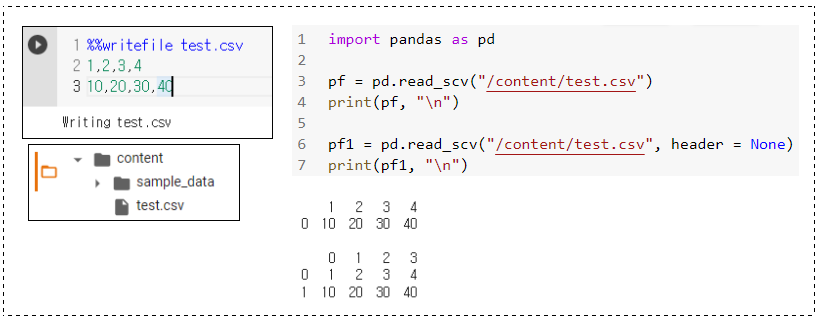
用法演示:读取 csv 文件
pf = pd.read_scv(“/content/test.csv”)
pf1 = pd.read_scv(“/content/test.csv”, header = None)
运行结果:
将下面的 vehicle_prod.csv 文件保存到 colab 的工作文件夹 “/content” 文件夹中:
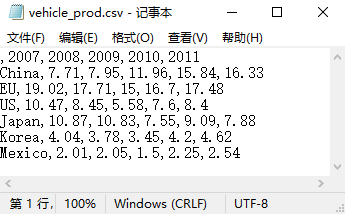
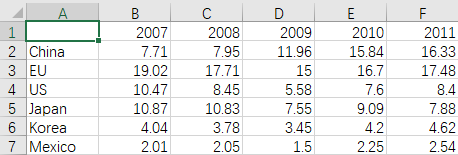
(若要将第一行用作索引,省略第1行第1列的名称)
然后在 colab 中选择该文件,然后右键单击,将出现 “复制路径” 选项。
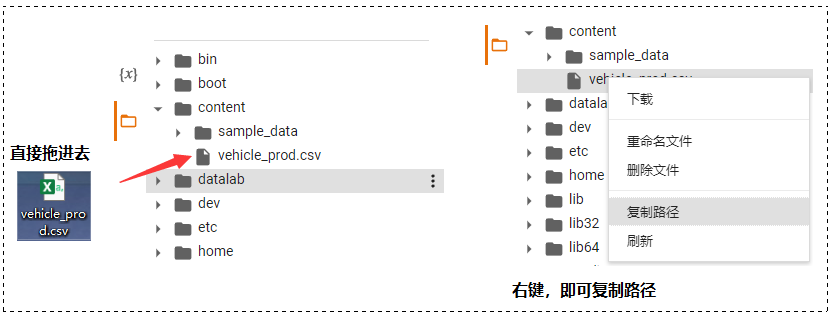
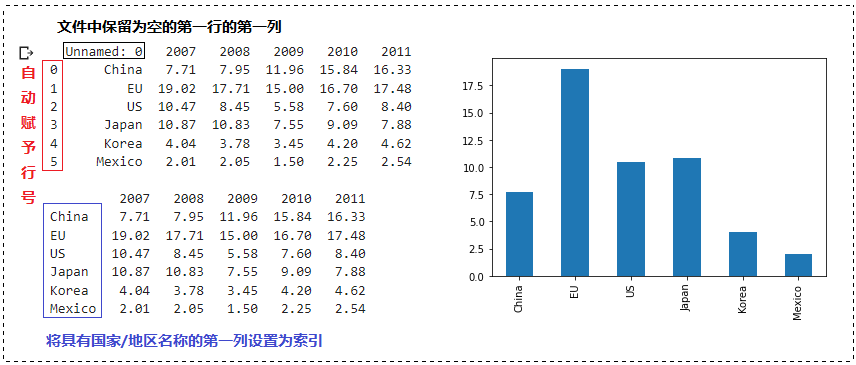
代码演示:读取 vehicle_prod.csv
import matplotlib.pyplot as plt
pf_f1 = pd.read_csv(“/content/vehicle_prod.csv”)
pf_f2 = pd.read_csv(“/content/vehicle_prod.csv”, index_col = 0)
pf_f2[“2007”].plot(kind=’bar’) # 将列”2007″的数据可视化
运行结果:
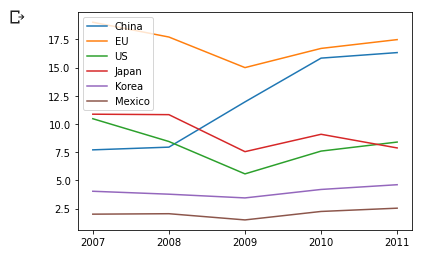
代码演示:读取 vehicle_prod.csv 文件,按国家/地区绘制年度产量图:
import matplotlib.pyplot as plt
pf_f = pd.read_csv(“/content/vehicle_prod.csv”, index_col = 0)
plt.plot(pf_f.loc[“China”])
plt.plot(pf_f.loc[“Japan”])
plt.plot(pf_f.loc[“Korea”])
plt.plot(pf_f.loc[“Mexico”])
plt.legend([“China”, “EU”, “US”, “Japan”, “Korea”, “Mexico”])
运行结果:
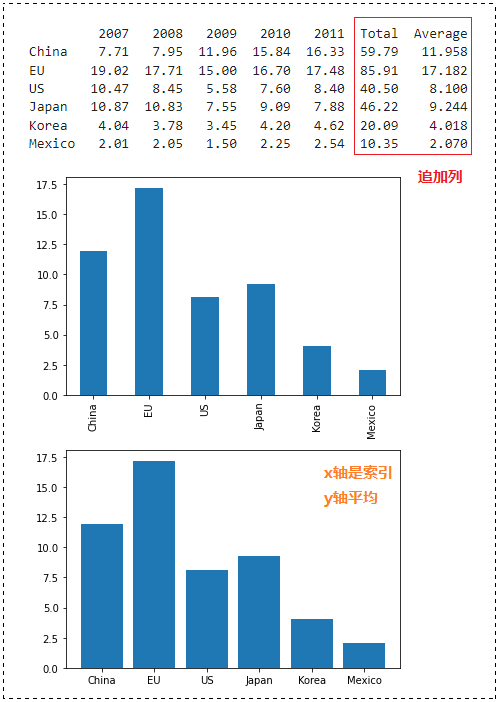
代码演示:读取 vehicle_prod.csv 文件进行统计(总计,平均值)
import matplotlib.pyplot as plt
pf_f = pd.read_csv(“/content/vehicle_prod.csv”, index_col=0)
## 函数的参数axis=1表示列方向,axis=0表示行方向
pf_f[“Total”] = pf_f.sum(axis=1)
pf_f[“Average”] = pf_f[[“2007”, “2008”, “2009”, “2010”, “2011”]].mean(axis=1)
pf_f[“Average”].plot(kind=’bar’)
plt.bar(pf_f.index, pf_f[“Average”])
运行结果: