昨天我的new bing申请下来了,有了聊天的界面:

但是解析pdf的英文文献,还是不行,没有对话窗口。就问了一下chatGPT,方案如下:
要使用New Bing解析PDF文献,你需要以下几个步骤:
1,申请加入new bing的等待名单,等待邮箱通知
2,收到new bing的邀请通知
3,安装Edge 开发者12版本:Edge DEV
4,用Edge DEV打开pdf,打开对话窗口,就可以沟通了。
下面结合我的经验,介绍一下相关步骤。
1. 申请new bing的waitlist名单
详见我的文章:
如何使用微软bing的chatGPT

注意:
- 不要用126,163,qq邮箱,可以用outlook和gmail邮箱
- 注册后,会收到一封邮件
- 要12~15天左右才能收到确认邮件
2. 收到new bing的邀请通知
详见我的文章:
过了!!!我可以用new bing的chatGPT了
用了12天收到的确认邮件:
3. 安装Edge Dev版本才能解析pdf文献
下载地址:https://www.microsoftedgeinsider.com/en-us/download/dev

安装一下,打开界面如下,右上角有个图标:

4. 用Edge Dev打开英文pdf文献
比如,这里打开一篇水产的英文文献pdf
选择浏览器右上角的图标,进入对话框:

5. 开始询问
5.1 这篇文章主要内容介绍
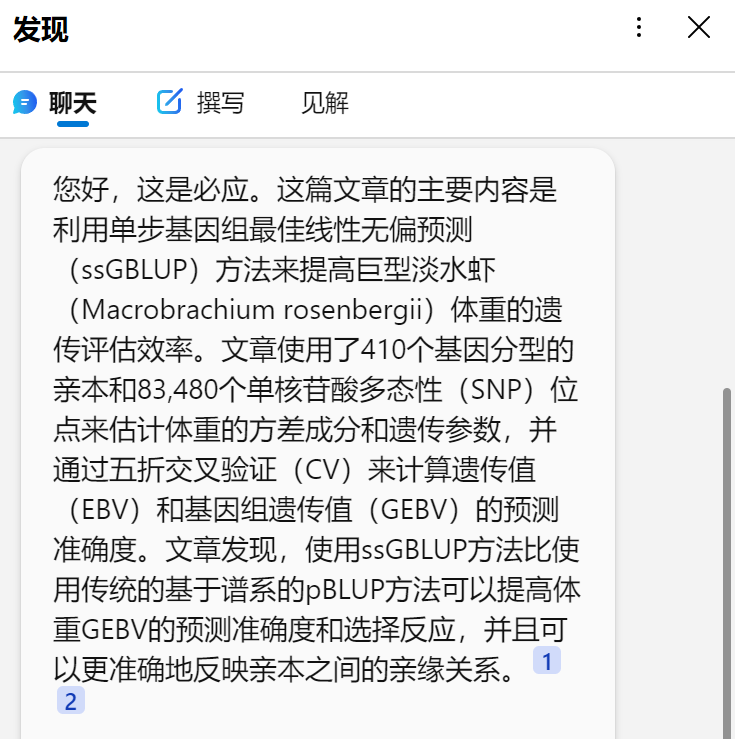
您好,这是必应。这篇文章的主要内容是利用单步基因组最佳线性无偏预测(ssGBLUP)方法来提高巨型淡水虾(Macrobrachium rosenbergii)体重的遗传评估效率。文章使用了410个基因分型的亲本和83,480个单核苷酸多态性(SNP)位点来估计体重的方差成分和遗传参数,并通过五折交叉验证(CV)来计算遗传值(EBV)和基因组遗传值(GEBV)的预测准确度。文章发现,使用ssGBLUP方法比使用传统的基于谱系的pBLUP方法可以提高体重GEBV的预测准确度和选择反应,并且可以更准确地反映亲本之间的亲缘关系。
5.2 这篇文章用的是什么方法
这篇文章用的是单步基因组最佳线性无偏预测(ssGBLUP)方法。这是一种结合了基于谱系的pBLUP方法和基于分子标记的GBLUP方法的遗传评估方法。它可以利用少量的基因分型数据和大量的表型数据来构建一个更准确的亲缘关系矩阵H,从而提高遗传值和基因组遗传值的预测准确度和选择反应。
您想了解更多关于ssGBLUP方法的原理或步骤吗?
5.3 请问ssGBLUP方法有什么优势或局限性
ssGBLUP是一种基于基因组和谱系信息的单步最佳线性无偏预测方法,用于动物育种中的遗传评估和选择。ssGBLUP方法有以下优势和局限性:
优势:ssGBLUP可以利用高密度SNP标记来构建更准确的亲缘关系矩阵,从而提高遗传参数的估计精度和育种值的预测准确度1234。ssGBLUP还可以利用不同权重的SNP标记来进行基因组广泛关联分析(GWAS),从而发现与目标性状相关的SNP位点。ssGBLUP还可以适用于任何类型的群体,包括有或无谱系信息、有或无基因组信息、有或无近交等。
局限性: ssGBLUP需要大量的计算资源和时间来处理大规模的数据集,尤其是当亲缘关系矩阵非常稠密时3。ssGBLUP还需要对SNP标记进行质量控制和过滤,以避免引入噪声和偏差。ssGBLUP还可能受到群体结构、选择历史、遗传漂变等因素的影响,从而降低预测效果。
希望这些信息对您有所帮助。
会给出一个参考文献:

5.4 文章主要是使用什么软件,什么参数实现的
文章中使用了单步基因组最佳线性无偏预测(ssGBLUP)方法来估计遗传参数和预测遗传增益。ssGBLUP方法是一种利用高密度基因型数据进行遗传评估的流行方法1。文章中使用了动物模型,结合SNP标记和家系数据构建的关系矩阵H或者只用家系数据构建的关系矩阵A来估计方差组分。文章中没有提到具体使用的软件和参数,但根据其他文献23,可能使用的软件有BLUPF90、ASReml、WOMBAT等,可能使用的参数有SNP标记数目、交叉验证次数、选择强度等。
ASReml是一种用于拟合线性混合模型的软件,可以处理大规模的数据和复杂的方差协方差结构1。ASReml的实现方法主要是基于平均信息算法(AI),利用似然函数和其一阶和二阶导数来估计参数2。ASReml有两种参数化方式,一种是基于比例(gamma)的,另一种是基于分量(sigma)的,具体取决于残差模型的设定2。ASReml还有一个R语言接口(ASReml-R),可以在R环境中进行数据处理、分析和输出管理
5.5 文章中遗传进展是如何计算的
遗传进展是指在一定的选择压力下,一个群体的遗传水平随着世代的变化而发生的改变1。文章中遗传进展是用选育值或基因选育值(EBV或GEBV)的差异来计算的。选育值或基因选育值是指一个个体对后代表现的预期贡献,它可以用线性混合模型来估计2。文章中使用了五折交叉验证法(CV)来评估选育值或基因选育值的准确性,然后根据不同世代之间的平均选育值或基因选育值的差异来计算遗传进展。